

Redis 란

레디스 란 Romete Dictionary Server 의 약자 이며, Key-Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터베이스 관리 시스템 입니다.
쉽게 말하자면, 데이터 처리속도가 빠른 NoSQL 데이터베이스 입니다.
TMI
Redis 는 RDBMS 와 비교했을 때 빠른 속도를 장점으로 가지고 있습니다.
이유는 RDBMS 의 경우에는 데이터를 디스크에 저장하지만, Redis 의 경우에는 메모리에 데이터를 저장하게 됩니다. 그러므로 속도면에서 굉장히 빠른 성능을 보여줍니다. 하지만 이에 따른 단점도 분명하기에 궁금하시다면 찾아보시는 것을 추천드립니다.(현대 컴퓨터의 메모리의 용량은 한정적이기 때문입니다. 조만간.. 잡히겠지만)
Redis 너 그래서 어디에 쓰는데?
Redis의 사용 사례는 아주 다양합니다.
- 캐싱
- 세션 관리
- 실시간 분석 및 통계
- 메시지 큐
- 지리공간 인덱싱
- 속도 제한
- 실시간 채팅 및 메시징
Redis 의 다양한 사용 방식이 존재 하지만, 이 게시글에서는 캐싱에 대한 이야기만 다룰 것입니다. 다른 사례의 내용도 적용하게 된다면 포스팅 하도록 하겠습니다.
캐시, 캐싱이란?
캐시란 원본 저장소보다 빠르게 가져올 수 있는 임시 데이터 저장소를 의미합니다.
캐싱이란 캐시에 접근해서 데이터를 빠르게 가져오는 방식을 의미합니다.

캐시는 일상속 웹 브라우저, 동영상 스트리밍, 전자상 거래 등 다양한 곳에서 사용됩니다.
데이터 캐싱 전략(CacheAside, Write Around)
데이터를 캐싱하는 전략에 많은 전략들이 있습니다. 여기서는 CacheAside 와 WriteAround 전략에 대해서 알아보도록 하겠습니다.
Cache Aside - read
Cache Aside 의 경우 조회 요청이 들어왔을 때 캐시를 먼저 확인하고 데이터가 있다면 응답(그림1), 없다면 데이터 베이스에서 데이터를 캐시에 저장하고 응답(그림2)합니다.
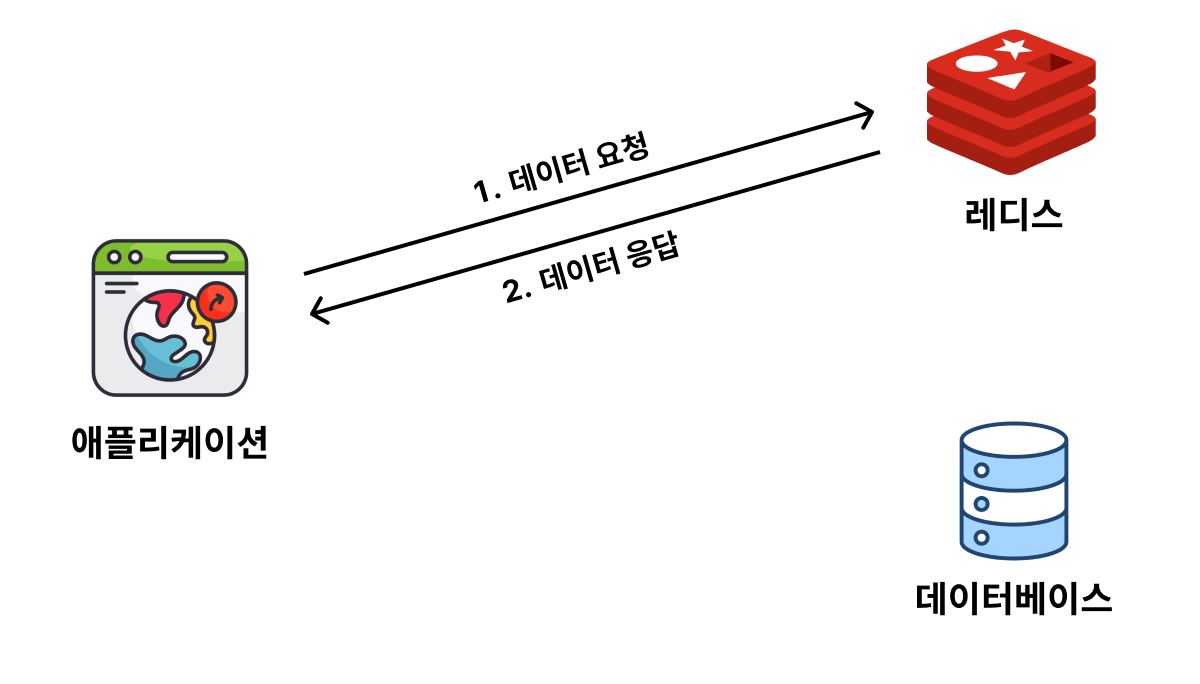

위 과정에서 그림1의 과정 처럼 데이터가 있다면 Cache Hit, 그림2 처럼 데이터가 없다면 Cache Miss 라고 합니다.
Write Around -write
WriteAround 는 쓰기 전략입니다. 데이터를 저장할 때 레디스에 저장하지 않고 바로 데이터베이스에 저장하게 됩니다. (그림3)

CacheAside, writeAround 의 한계
캐시된 데이터가 항상 일관성을 유지할 수 없지 않나? 라는 의문이 생길 것입니다. (캐시된 데이터는 새로 등록된 데이터를 가지고 있지 않아 데이터베이스와 캐시의 데이터의 불일치 합니다.)
이는 실시간으로 운영되는 애플리케이션에서는 치명적입니다. 이를 해결 하기 위해서는 어떤 방법을 사용할까요?
이 부분에 대해서는 완벽하게 한계를 극복하기는 힘듭니다. 실시간으로 동기화를 하면 되는거 아닌가? 라는 의문을 가질 수 있지만 요청이 많이 들어오는 과정에서 실시간으로 동기화하게 되면 서버에 악영향을 끼치기 때문입니다. 빠른 조회의 장점을 가지지만 데이터의 일관성을 포기하고 택하게 되는 것입니다. 캐시를 적용할 데이터는 신중히 선택해야 합니다.
- 자주 조회되는 데이터
- 잘 변하지 않는 데이터
- 실시간으로 정확하게 일치하지 않아도 되는 데이터
위의 데이터들의 캐시를 적용시키기 적절합니다. 하지만 장기간 데이터를 동기화 시키지 않는 것은 문제가 됩니다. 이 때 저희는 Redis의 TTL 기능을 사용합니다.
만료 기간을 설정해주고 데이터가 만료, 삭제 된 후 (데이터가 만료 시간 후 삭제 되기 때문에 한정적인 메모리 공간도 효율적으로 사용할 수 있음.) Cache Miss 과정을 통해 데이터가 다시 동기화 됩니다.
하지만 DB 의 성능향상의 기본은 SQL 튜닝입니다.!
2024.12.12 - [DB] - SQL 최적화 (실행 계획으로 찾아보기)- MySQL
Redis 명령어
Redis 의 명령어에 대해서 알아보도록 하겠습니다. 더 많은 명령어도 존재하지만 여기서는 7가지의 기본 명령어에 대해서만 알아보겠습니다.
SET, GET, KEYS, DEL, SET EX, TTL, FLUSHALL
# set -> taedong:name 이라는 키와 kimtaedong 이라는 값으로 데이터를 저장합니다.
127.0.0.1:6379> set taedong:name "kimtaedong"
OK
127.0.0.1:6379> set taedong:hobby "balling"
OK
# get -> taedong:name 이라는 키 값으로 kimtaedong 이라는 값을 찾아옵니다.
127.0.0.1:6379> get taedong:name
"kimtaedong"
127.0.0.1:6379> get taedong:hobby
"balling"
# keys -> 저장된 키의 값을 찾을 수 있습니다.
127.0.0.1:6379> keys *
1) "taedong:name"
2) "taedong:hobby"
#del -> 키의 값으로 데이터를 삭제할 수 있습니다.
127.0.0.1:6379> del taedong:name
(integer) 1
127.0.0.1:6379> del taedong:hobby
(integer) 1
#set ex -> set 으로 키와 값을 정해주고 만료 시간을 정해줄 수 있습니다. 만료 시간후 삭제됩니다.
127.0.0.1:6379> set taedong:name "kimtaedong" ex 10
OK
127.0.0.1:6379> get taedong:name
(nil)
127.0.0.1:6379> set taedong:name "kimtaedong" ex 30
OK
#ttl -> ttl 명령어로 데이터의 만료시간을 확인할 수 있습니다.
127.0.0.1:6379> ttl taedong:name
(integer) 23
#flushall 모든 데이터를 삭제할 수 있습니다.
flushall
Redis Key naming
Redis 의 Key 이름을 짓는 것은 중요합니다. 다양한 컨벤션이 존재하겠지만 아래의 컨벤션을 기억해봅시다.
#사용자 중 PK 가 100인 사용자의 프로필
users:100:profile
#게시글 중 PK 10 인 게시글의 댓글
post:10:comment컨벤션의 장점
- 가독성 : 데이터의 의미와 용도를 쉽게 파악할 수 있다.
- 일관성 : 컨벤션을 따름으로써 코드의 일관성이 높아지고 유지보수가 쉬워진다.
- 검색 및 필터링 용의성 : 패턴 매칭을 이용해 특정 유형의 key 를 쉽게 찾을 수 있다.
- 확장성 : 서로 다른 Key 와 이름이 겹쳐 충동할 일이 적다.
Spring Boot + Redis 예제
개발 환경
java-version : 17
Spring Boot : 3.x.x
MySQL : 8.x.x
Redis : 3.0.5
의존성 : web, devtools, redis, jpa, mysql, lombok
위에서 레디스에 대한 개념과 캐싱 방법 명령어 등에 대해 알아보았습니다. 하지만 실제로 코드를 쳐봐야 느낌이 오겠죠? 설정 코드와 간단한 서비스로직을 작성하고 성능 비교를 해보겠습니다.
Entity
@Entity
@Table(name = "boards")
@Getter
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
@CreatedDate
@JsonFormat(pattern = "yyyy-MM-dd'T'HH:mm:ss")
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
private LocalDateTime createdAt;
}
Controller
@RestController
@RequestMapping("boards")
@RequiredArgsConstructor
public class BoardController {
private final BoardService boardService;
// paging 을 통한 데이터를 가져오는 컨트롤러
@GetMapping()
public List<Board> getBoards(
@RequestParam(defaultValue = "1") int page, @RequestParam(defaultValue = "10") int size
){
return boardService.getBoards(page, size);
}
}
Service
@Service
@RequiredArgsConstructor
public class BoardService {
private final BoardRepository boardRepository;
@Cacheable(cacheNames = "getBoards", key = "'boards:page:' + #page + ':size:' + #size", cacheManager = "boardCacheManager")
public List<Board> getBoards(int page, int size){
Pageable pageable = PageRequest.of(page -1 , size);
Page<Board> pageOfBoards = boardRepository.findAllByOrderByCreatedAtDesc(pageable);
return pageOfBoards.getContent();
}
}
Repository
public interface BoardRepository extends JpaRepository<Board, Long> {
Page<Board> findAllByOrderByCreatedAtDesc(Pageable pageable);
}
RedisConfig
@Configuration
public class RedisConfig {
//yml 파일의 벨루를 가져와서 사용하는 것이다.
@Value("${spring.data.redis.host}")
private String host;
//yml 파일의 벨루를 가져와서 사용하는 것이다.
@Value("${spring.data.redis.port}")
private int port;
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
// Lettuce라는 라이브러리를 활용해 Redis 연결을 관리하는 객체를 생성하고 Redis 서버에 대한 정보를 생성한다.
return new LettuceConnectionFactory(new RedisStandaloneConfiguration(host, port));
}
}
RedisCacheConfig
@Configuration
@EnableCaching
public class RedisCacheConfig {
@Bean
public CacheManager boardCacheManager(RedisConnectionFactory redisConnectionFactory) {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration
.defaultCacheConfig()
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new StringRedisSerializer()))
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new Jackson2JsonRedisSerializer<Object>(Object.class)
)
)
.entryTtl(Duration.ofMinutes(1L));
return RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(redisCacheConfiguration)
.build();
}
}
application.yml
spring:
profiles:
default: local
datasource:
url: jdbc:mysql://localhost:3306/mydb
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
show-sql: true
data:
redis:
host: localhost
port: 6379
logging:
level:
org.springframework.cache : trace # Redis ??? ?? ??? ????? ??
예제를 작성한 후 더미 데이터를 100만건을 넣어주겠습니다. 데이터를 넣는 부분은 생략하도록 하겠습니다.
PostMan 을 통해 Test 를 진행하도록 하겠습니다.


캐시 전 데이터를 조회 했을 때 1.27s 가 걸리는 것을 확인 할 수 있습니다. 이 과정에서 Cache Miss 가 발생하고 되고 Redis 에 데이터가 캐시 됩니다. 그 과정이 지나고 다시 조회 하게 되면 33ms 로 성능이 눈에 띄게 좋아지는 것을 확인할 수 있습니다. 극단적으로 봤을 때 38.5배의 성능이 향상된 것입니다. 하지만 잘 정리하고 알아보고 사용하는 것은 중요하다.
위에 코드를 보면 알 수 있지만 굉장히 많은 팩토리 패턴, 템플릿 메소드 패턴, 전략 패턴이 사용 된 것을 알 수 있습니다.Lettuce 라이브러리를 사용해 redis 연결관리 하는 객체를 생성하고 서버에 대한 정보를 생성합니다. 그 후 추상화 된 CacheManager 에서 구현체로 RedisCacheManager 를 사용하는 것을 알 수 있습니다. 이렇다 보니 디자인 패턴에 대해서 도 잘 알아야 코드를 이해하는 것이 편해진다고 생각합니다. 디자인 패턴에 대한 게시글도 작성해보도록 하겠습니다.
요약
- Redis 는 데이터 처리 성능이 뛰어난 NoSQL 이다.
- 캐시는 데이터 저장소에 있는 데이터를 빠르게 읽어오기 위한 저장소이다. 캐싱은 데이터를 저장하는 방법이다.
- 캐시에 데이터가 존재한다면 CacheHit 존재하지 않는다면 Cache Miss 가 발생한다.
- CacheAride 와 WriteAround 의 한계는 분명하지만, 장점을 보고 사용한다.
다음 게시글은 부하 테스트를 하는 게시글입니다. 긴 글 읽어주셔서 감사합니다. 꾸벅(_ _ ;)