

백엔드 서버 개발을 하다보면 DB 성능에 대해 고민하게 됩니다.
SQL 최적화를 데이터 조회의 시간을 단축 시킬 수 있고, 이는 성능향상과 직결되는 부분이 될 것입니다.
오늘은 DB 성능의 개선법과, MySQL 의 아키텍처 그 중 에서도 SQL 튜닝에 대해 알아보도록 하겠습니다.
DB 성능 개선의 방법
- SQL 튜닝
- 캐싱 서버 활용
- 레플리케이션 (Master/Slave)
- 샤딩
- 스케일 업
DB 성능 개선을 위해서는 다양한 방법을 고려할 수 있습니다.
캐싱 서버 활용, 레플리케이션, 샤딩, 스케일 업의 경우에는 설정 추가 및 비용 추가가 발생할 수 있는 조치 사항입니다.
하지만 SQL 튜닝은 시스템 변경 및 비용 추가 없이 성능을 개선할 수 있습니다.
MySQL 의 아키텍처
- MySQL 의 아키텍처를 먼저 파악하고 어떤 부분에서DB 성능 저하가 발생하는지 알아보도록 하겠습니다.

1. 클라이언트가 DB 로 요청을 보냅니다.
2. 옵티마이저가 클라이언트의 SQL 을 분석하고 효율적인 계획을 세워 스토리지 엔진에서 데이터를 가져옵니다.
3. 엔진에서 필요한 정렬, 필터링의 후처리 후 클라이언트에게 응답합니다.
DB 의 성능 저하는 2번째 과정에서 일어납니다.
여기서 주의할 점은 옵티마이저의 계획이 완벽하지는 않다는 것입니다.
스토리지 엔진에서 데이터를 찾을 때 너무 많은 데이터를 가져오거나 찾기 어려운 데이터일수록 많은 시간을 필요로합니다. 이 부분에서 SQL 튜닝을 통해 데이터를 찾기쉽게 바꾸고, 적은 양의 데이터를 가져올 수 있게끔 튜닝해야 합니다.
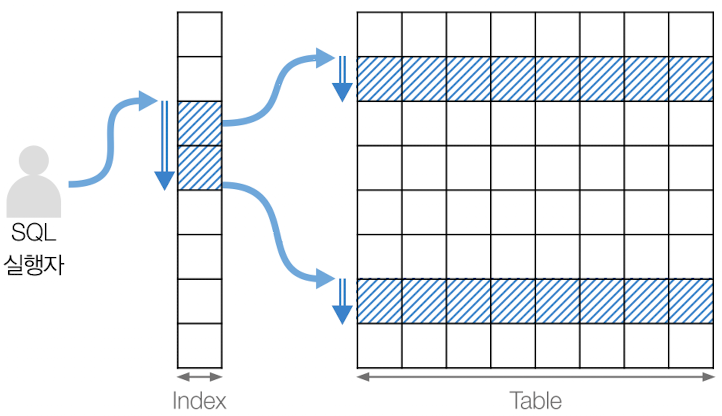
INDEX 란?
INDEX 를 통해 쿼리 최적화를 한다는 이야기를 많이 들었습니다. 인덱스란 무엇일까요?
인덱스의 정의는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료구조 입니다.
직관적으로 말하면 데이터를 빨리 찾기위해 특정 컬럼을 기준으로 미리 정렬해놓은 표입니다.

인덱스를 설정하게 되면 설정한 컬럼을 기준으로 정렬이 됩니다. 그 후 찾고자 하는 데이터에 바로 접근할 수 있습니다.
간단한 쿼리로 실습 해보도록 하겠습니다.
버전 및 툴
실행 환경 : MySQL 8.x.x
TOOL : DataGrip
데이터의 삽입 과정은 생략하도록 하겠습니다.
select * from users where age = 23;
create index idx_age on users(age);
# 198ms -> 150 ms위의 쿼리에서 나이가 23인 user 의 정보를 가져오는 쿼리입니다.
이때 where 절에서 사용되는 칼럼 age 에 index 를 걸어주게 되면 48ms 의 성능이 개선된 것을 확인할 수 있습니다.
INDEX 의 종류
- 클러스터링 인덱스
- 고유 인덱스
- 멀티 컬럼 인덱스
- 커버링 인덱스
클러스터링 인덱스
클러스터링 인덱스란 원본 데이터 자체가 정렬되는 인덱스를 말합니다. 클러스터링은 PK 밖에 존재하지 않습니다.
PK 에는 기본적으로 인덱스가 적용됩니다. 그렇기 때문에 PK 를 기준으로 데이터가 정렬됩니다.
고유 인덱스
고유 인덱스는 UNIQUE 속성을 가지는 컬럼에서 생성되는 인덱스 입니다.
create table test_table(
id int AUTO_INCREMENT primary key ,
name varchar(100) unique
);유니크 속성 컬럼을 생성하게 되면 아래와 같이 고유 인덱스가 생성되는 것을 알 수 있습니다.

멀티 컬럼 인덱스
멀티 컬럼 인덱스는 여러개의 컬럼을 묶어 설정한 인덱스 입니다.
CREATE INDEX idx_부서_이름 ON users (부서, 이름);위와 같이 부서, 이름 두가지 컬럼을 묶어 사용하는 인덱스 입니다.
하지만 몇가지 주의사항이 존재합니다.
- 멀티 컬럼 인덱스를 구성할 때는 소분류에서 부터 큰 분류로 설정해야 합니다.
- 일반적으로 소분류 데이터의 개수가 큰 분류의 데이터보의 수보다 적기 때문에 소분류의 데이터를 탐색하는 것이 더 빠릅니다. 소분류를 먼저 탐색하고, 대분류를 탐색하는게 빠르다.
- 단일 인덱스를 사용했을 때 성능차이가 없다면, 단일 인덱스를 사용해야 하는것이 좋습니다.
- 멀티 컬럼인덱스를 일반 인덱스처럼 활용하지 못하는 경우가 있습니다.
- 먼저 배치된 컬럼의 인덱스만 단일 인덱스 처럼 사용이 가능합니다.
커버링 인덱스
SQL 문을 실행시킬 때 필요한 모든 컬럼을 갖고 있는 인덱스를 커버링 인덱스라고 합니다.
쉽게 생각하면 조회해야 하는 모든 컬럼이 인덱스로 해결이 가능한 것입니다.
이 경우에는 디스크 I/O 를 줄일 수 있습니다. 하지만 인덱스의 개수가 늘어나게 되면 쓰기 성능이 낮아지는 점을 유의 해야 합니다.
실행 계획(EXPLAIN)을 통해 성능 저하 요인 찾기
EXPLAIN SELECT * FROM USERS;EXPLAIN 을 사용해 실행계획을 확인할 수 있습니다. 이를 통해서 성능 저하 요인을 찾아볼 수 있습니다.

위의 명령문을 실행하게 되면 위와 같은 결과가 나오게 됩니다. 여기서 중요한 부분들에 대해서만 간단히 설명하겠습니다.
id : 순서
type : index scan 의 타입 (아래 글 작성)
possible key : 사용가능 한 키의 리스트
key : 실제 사용 키
rows : 테이블에 접근 한 엑세스 수 (이 값을 어떻게 줄일지 고민 하는 것이 튜닝의 킥)
EXPLAIN ANALYZE SELECT * FROM USERS;EXPLAIN ANALYZE 를 통해 세부적인 실행계획을 확인할 수 있습니다.

Table scan on USERS : 테이블을 풀스캔
rows : 접근한 데이터의 행의 수
actual time : 앞 숫자 - 첫 번째 데이터에 접근 시간 , 뒷 숫자 - 마지막 데이터까지 접근한 시간
조건을 추가하게 되면 Filter 라는 행이 생기고 조건에 대해 설명합니다.
실행계획의 index scan 타입
- ALL
- INDEX
- CONST
- RANGE
- REF
ALL
풀 테이블 스캔을 의미합니다. 인덱스를 활용하지 않고 테이블을 처음부터 끝까지 전부 다 뒤져서 데이터를 찾는 방식입니다. 비효율적인 방법입니다.

INDEX
풀 인덱스 스캔을 의미합니다. 인덱스 테이블을 모두 찾는 방식입니다. 이는 풀 테이블 스캔보다는 효율적이지만 아주 효율적이진 않습니다.

CONST
1개의 데이터를 바로 찾을 수 있는 경우입니다. 조회하고자 하는 데이터를 바로 찾을 수 있는 스캔입니다.
고유 인덱스, 기본 키를 사용해 검색하는 방법입니다. 이 방식은 굉장히 효율적입니다.

RANGE
인덱스 레인지 스캔은 인덱스를 활용해 범위 형태의 데이터를 조회한 경우를 의미합니다. 범위 형태란
부등호, IN, LIKE, BETWEEN 을 활용한 데이터 조회를 뜻합니다. 이 경우는 효율적인 방법입니다. 하지만 범위가 너무 커질 경우 성능 저하의 원인이 되기도 합니다.
REF
비고유 인덱스를 사용한 경우 입니다. UNIQUE 가 아닌 칼럼의 인덱스를 사용한 경우에 발생하는 경우입니다.

쿼리 최적화!
100만개의 더미 데이터를 넣고 최적화 해보도록 하겠습니다.
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 더미 데이터 삽입 쿼리
INSERT INTO users (name, department, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
CASE
WHEN n % 10 = 1 THEN 'Engineering'
WHEN n % 10 = 2 THEN 'Marketing'
WHEN n % 10 = 3 THEN 'Sales'
WHEN n % 10 = 4 THEN 'Finance'
WHEN n % 10 = 5 THEN 'HR'
WHEN n % 10 = 6 THEN 'Operations'
WHEN n % 10 = 7 THEN 'IT'
WHEN n % 10 = 8 THEN 'Customer Service'
WHEN n % 10 = 9 THEN 'Research and Development'
ELSE 'Product Management'
END AS department, -- 의미 있는 단어 조합으로 부서 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
우선 기본적으로 불러오는 데이터의 개수를 줄이면 DB 의 성능이 향상됩니다.
WHERE 절이 사용된 쿼리를 최적화 해보겠습니다.
WHERE 이 사용된 쿼리
SELECT * FROM users
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY);
EXPLAIN SELECT * FROM users
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY);
# full table scan 이 일어난다.
CREATE INDEX idx_created_at ON users (created_at);
# 557ms -> 146ms이 경우에 인덱스를 선언하기 전 557 ms 의 시간이 사용되었습니다. 하지만 WHERE 절의 칼럼에 인덱스를 추가해준 후 146ms 로 3배 정도의 성능 향상된 것을 확인할 수 있습니다.
WHERE 문의 IN, BETWEEN, LIKE 이 사용되는 칼럼에 인덱스를 사용했을 때 성능이 향상될 가능성이 높습니다.
# 인덱스 설정 전
-> Filter: ((users.department = 'Sales') and
(users.created_at >= <cache>((now() -interval 3 day)))) (cost=188816 rows=66447)
(actual time=57.2..671 rows=211 loops=1)
-> Table scan on users (cost=188816 rows=1.99e+6)
(actual time=43.2..543 rows=2e+6 loops=1)
# 인덱스 설정 후
-> Filter: (users.department = 'Sales')
(cost=1356 rows=217)
(actual time=0.117..31.8 rows=211 loops=1)
-> Index range scan on users using idx_created_at over
('2024-12-09 15:54:35' <= created_at),
with index condition: (users.created_at >= <cache>((now() - interval 3 day)))
(cost=1356 rows=2166) (actual time=0.0835..31.3 rows=2166 loops=1)인덱스를 설정하기 전에는 풀 테이블 스캔이 일어난 것을 알 수 있습니다. 2의 6승의 rows 에 접근하는 것을 알 수 있습니다. 하지만 인덱스를 설정한 후 에는 인덱스 레인지 스캔을 통해 2166개의 rows 에만 접근하는 것을 알 수 있습니다.
다음은 WHERE 절에 여러개의 조건이 있을 때의 상황을 한 번 알아보도록 하겠습니다.
SELECT * FROM users
WHERE department = 'Sales'
AND created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY);이 경우에는 3가지의 방법을 생각할 수 있습니다.
- created_at
- department
- 두가지 다
created_at
SELECT * FROM users
WHERE department = 'Sales'
AND created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY);
Create INDEX idx_create_at on users (created_at);
# 590ms -> 166ms
department
SELECT * FROM users
WHERE department = 'Sales'
AND created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY);
create index idx_department on users(department);
# 590ms -> 12s 590ms
두가지 다
SELECT * FROM users
WHERE department = 'Sales'
AND created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY);
create index idx_create_at_department on users (department, created_at);
#590ms -> 143ms
#created_at
-> Filter: (users.department = 'Sales')
(cost=1398 rows=216)
(actual time=0.224..6.95 rows=210 loops=1)
-> Index range scan on users using idx_create_at over
('2024-12-09 16:05:38' <= created_at),
with index condition:
(users.created_at >= <cache>((now() - interval 3 day)))
(cost=1398 rows=2161) (actual time=0.0303..6.82 rows=2161 loops=1)
#department
-> Filter: (users.created_at >= <cache>((now() - interval 3 day)))
(cost=20721 rows=123181)
(actual time=54.8..13647 rows=210 loops=1)
-> Index lookup on users using idx_department (department='Sales')
(cost=20721 rows=369580)
(actual time=5.52..13610 rows=200000 loops=1)
#두가지 다
-> Index range scan on users using idx_create_at_department over
(department = 'Sales' AND '2024-12-09 16:08:52' <= created_at),
with index condition:
((users.department = 'Sales')
and
(users.created_at >= <cache>((now() - interval 3 day))))
(cost=190 rows=210) (actual time=0.0271..50.9 rows=210 loops=1)
3가지의 경우를 다 살펴 보았습니다. created_ at 을 추가했을 때 2000개의 rows , department 의 경우 약 37만개의 rows 두가지의 다의 경우 210 개의 rows 에 접근하는 것을 알 수 있습니다.
만약, 멀티 컬럼의 인덱스와 단일 인덱스 컬럼의 성능향상이 비슷하다면 단일 인덱스를 사용하는 것을 추천합니다.
인덱스를 인식하지 않는 경우
- 넓은 범위의 데이터를 검색하는 경우
- 인덱스를 생성한 컬럼을 가공하는 경우
2번의 경우를 살펴보겠습니다. 데이터를 삽입하는 과정은 생략하겠습니다.
CREATE INDEX idx_name ON users (name);
CREATE INDEX idx_salary ON users (salary);
EXPLAIN SELECT * FROM users
WHERE salary * 2 < 1000
ORDER BY salary;
index 를 추가했지만 풀테이블 스캔을 한것을 알 수 있습니다. 인덱스를 생성한 칼럼을 가공하게 되면 인덱스를 활용하지 못하는 경우가 생깁니다. 이 경우에는 인덱스의 칼럼 수정하지 말고 수식을 수정하는 것이 바람직 합니다.
ORDER BY 이 사용된 쿼리
EXPLAIN ANALYZE SELECT * FROM users
ORDER BY salary
LIMIT 100;
# 340ms -> 60 ms
# 정렬을 활용해야 하는 방법을 인덱스를 활용하면 된다. 인덱스 또한 정렬이기 때문이다.
create index idx_salary on users(salary);
여기서 우리는 생각할 수 있습니다. 인덱스를 사용하게 되면 정렬이 된다는 것을요!! . 풀 테이블 스캔에서 인덱스 풀 테이블 스캔으로 향상된 것을 확인할 수 있습니다. 또한 LIMIT 를 사용하지 않고 조회하게 된다면 굉장히 넓은 범위의 데이터이기 때문에 풀테이블 스캔으로 데이터를 가져오게 됩니다.
WHERE 문 INDEX vs ORDER BY문 INDEX
우리는 지금까지 WHERE 문 인덱스와 ORDER BY 문 인덱스에 대해 확인하고 코드로 확인해보았습니다.
그렇다면 WHERE 문과 ORDER BY 문 둘 중 어디에 인덱스를 생성하는게 효율적일까요 ?
코드로 보겠습니다.
# order by index 추가
SELECT * FROM users
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY)
AND department = 'Sales'
ORDER BY salary
LIMIT 100;
create index idx_salary on users (salary);
# 339ms -> 5s 169ms
# create_at index 추가
SELECT * FROM users
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY)
AND department = 'Sales'
ORDER BY salary
LIMIT 100;
create index idx_create_at on users(created_at);
#339ms -> 111msWHERE 문에 인덱스를 생성하게 되면 range 스캔을 order by 에 생성하게 되면 풀테이블 스캔 및 풀 인덱스 스캔이 일어나게 됩니다. 그러므로 WHERE 문에 인덱스를 생성하는 것을 지향하는 것이 좋습니다.
HAVING 문 쿼리
SELECT age, MAX(salary) FROM users
GROUP BY age
HAVING age >= 20 AND age < 30;그룹함수를 사용했을 때 HAVING 을 통해 조건을 설정할 수 있습니다. 하지만 이경우에는 where 절로 옮겨주는 것이 더 효율적입니다.
EXPLAIN ANALYZE SELECT age, MAX(salary) FROM users
GROUP BY age
HAVING age >= 20 AND age < 30;
# 619ms -> 3s 881ms
EXPLAIN ANALYZE SELECT age, MAX(salary) FROM users
WHERE age >= 20 AND age <30
GROUP BY age;
# 619ms -> 409ms
이 경우에는 INDEX 를 설정하지 않았습니다. 하지만 HAVING 절 보다는 WHERE 절에서 데이터를 먼저 필터링 해주는 것이 시간 단축이 더 효율적이라는 것을 알 수 있습니다.
요약
- 스토리지 엔진에서 데이터를 찾아올 때 찾기 힘든 데이터가 있거나 대량의 데이터를 찾아올 때 성능 저하가 발생합니다.
- 인덱스의 종류에는 클러스러링 인덱스, 고유 인덱스, 멀티 컬럼 인덱스, 커버링 인덱스가 있습니다.
- EXPLAIN 을 이용해 type , rows 등의 실행계획을 확인하고 성능 최적화를 준비할 수 있습니다.
- 테이블 스캔의 종류에는 ALL, INDEX, RANGE, REF, CONST 등이 있습니다.
- 데이터를 조회할 때 LIMIT 를 통해서 데이터의 개수를 최소화 하는 것이 좋습니다.
- WHERE 절에서 BETWEEN, IN, 부등호 등 범위를 조건으로 할 때 인덱스를 설정하면 성능향상의 가능성이 높습니다.
- WHERE 절에서 인덱스가 생성된 컬럼을 가공할 경우 인덱스 활용이 안 될 있기에 주의해야 합니다.
- ORDER BY 절 대신 INDEX 를 활용해 정렬할 수 있습니다.(대량 데이터시에는 유의 해야 합니다.)
- HAVING 절을 활용하기 보단 가능한한 WHERE 절을 활용하는 것을 지향합시다.
오늘 포스팅에서는 DB 성능개선법, INDEX, EXPLAIN 을 활용한 SQL 튜닝에 대해 알아보았습니다. 다음 시간에는 REDIS 를 활용한 DB 성능 개선에 대해 작성해보도록 하겠습니다. 감사합니다.